
How To Fix GMC Robots.txt Crawl Issues

If Google can’t see your pages, your products can’t sell.
If Google can’t see your pages, your products can’t sell.
One overlooked line in your robots.txt file can quietly block Googlebot, trigger disapprovals in Google Merchant Center, and wipe your product visibility across Shopping and PMax campaigns. It’s a silent killer, and it can hit performance hard.
Let’s fix it — fast.
What This Means (& Why It Hurts)
You’ll usually see the error flagged in Google Merchant Center with a message like:
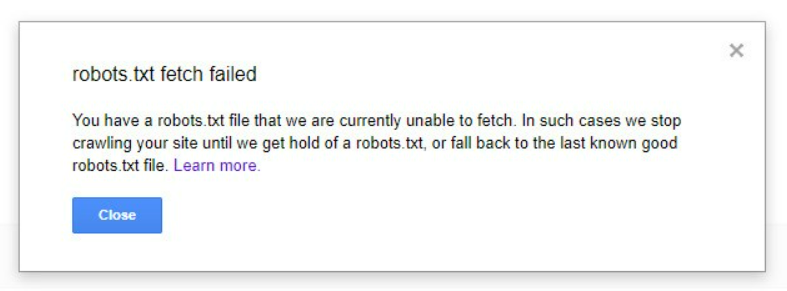
This means Google can’t verify landing page content. The outcome? Products may be:
Disapproved and pulled from Shopping ads
Excluded from search results
Mismatched on availability, since stock can’t be validated
In short, there’s a visibility gap between your product feed and what Google can crawl, and that’s a direct threat to performance.
Common Causes of Crawl Issues
We’ve seen the same culprits again and again when diagnosing robots.txt blocks:
Overly broad rules that block key resources like images or scripts
Blocked parameters that stop product URLs with tracking (e.g. ?sku=) from being crawled
Geo or IP restrictions that prevent Googlebot from accessing your site
CAPTCHA or firewall rules that unintentionally block bots
Migrations or CMS changes where the robots.txt file wasn’t updated correctly
Blocked images are especially damaging, as they can also trigger “Invalid image” warnings in Merchant Center.
How to Fix the robots.txt Issue
1. Allow Googlebot Access
Avoid blanket blocks like this:

That prevents all crawlers from accessing your site. Instead, use rules that explicitly allow Googlebot to access critical pages and resources:
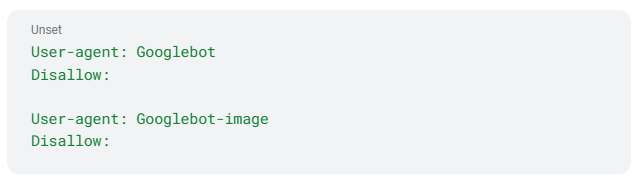
Make sure images and CSS/JS files are crawlable - they’re required for rendering your landing pages.
2. Review Disallowed Parameters
A common mistake is overuse of wildcards, e.g.:

This blocks any URL with a query string, including product parameters like ?sku= or ?variant=, which Merchant Center relies on.
Refine these rules so essential parameters aren’t blocked.
3. Test With Crawl Tools
Run diagnostics before every big feed update or site change. Use:
Google Search Console → URL Inspection Tool to check individual product URLs
Google Search Console → robots.txt Tester to confirm Googlebot can access your site correctly
Optional: you can also use trusted external validators like the TechnicalSEO robots.txt tester if you want to double-check syntax or broader crawler access — but Google’s own tools should always be your first stop.
✅ Always test a live product URL to confirm that Googlebot can fetch and render it.
What Happens If You Don’t Fix It
Robots.txt issues can escalate quickly:
Products disapproved within hours
Shopping ads stop serving
Sales drop while you wait 24–48 hours for a recrawl
Impression share lost to competitors with better crawl access
It’s a preventable performance bottleneck — but only if you catch it early.
Keeping Your Shopping Ads Live
Your robots.txt file may be small, but if it blocks Googlebot, it blocks revenue. Make robots.txt checks part of your pre-launch QA and ongoing feed management strategy to keep performance watertight.
How FeedSpark Can Help
Through our fully managed service, we proactively monitor feeds, websites, and structured data to identify issues early and keep Shopping campaigns running without interruption.
While we don’t directly manage robots.txt files, we:
Run daily audits to detect crawl blocks
Flag the exact causes of disapprovals
Give your tech team clear fixes to implement
Protect Shopping and PMax campaigns with proactive monitoring
Need help staying compliant and keeping your listings live? Let’s talk.
We’ll help you take control of your Merchant Center performance before errors impact your bottom line.